우리는 의사결정을 할 때 여러 가지 방법들을 사용한다.
주말 저녁, 연인과 데이트 코스를 정할 때는
레스토랑을 알아보며 블로그 후기 등을 찾을 것이고
친구들과 술자리가 예정되어 있다면
단체챗에서 회의를 통해 메뉴를 정하고
가게까지 서로의 거리가 비슷한 지역을 고를 수도 있다.
의사결정에 알게 모르게 여러 가지 데이터가 참고 지표로 사용되고 있는 것이다.
기업에서는 사업성의 판단이나 투자, 나아갈 방향 등
데이터를 훨씬 중요하게 여기며
자신의 데이터를 긁어가는(크롤링 등) 행위로
법적 분쟁까지 일어나고 있다.
이렇듯 데이터가 중요하다고 하는데
모든 것을 엔지니어에게 맡길 수는 없는 노릇이니
데이터를 다루는 방법을 알아보고자 한다.
그럼 대체 데이터는 뭘까?

In the pursuit of knowledge,
data is a collection of discrete values that
convey information, describing quantity,
quality, fact, statistics, other basic units of meaning,
or simply sequences of symbols that may be further interpreted
그것을 통해 무언가를 깨달을 수 있는 정보라기보단
특정 부분에 대한 자료 모음에 가깝다는 것이다.
퍼즐 조각이 아무리 많아도 흩어놓으면 그림을 볼 수 없는 법.
우리는 어떤 내용을 알기 위해 '데이터'라는 녀석을
뒤집고 자르고 조각내고 붙여서 가공해야만
원하는 정보를 얻을 수 있다.
그럼 데이터는 언제부터 이렇게 중요하게 되었을까.
이전에 Youtube에 대한 분석을 하며 스마트폰의 출시와 함께
세상은 달라졌다는 얘기를 했었다.
인터넷과 스마트폰의 발달이 있기 전에는
다량의 데이터를 수집하는 것조차 힘들었지만,
기술의 발전과 더불어 활용할 수 있는 정보의 양이 급속도로 늘어나버렸고
세계 경제 포럼은 2012년 떠오르는 10대 기술 중 그 첫 번째를
빅 데이터 기술로 선정하기에 이르렀다.
여기서 의문이 한 가지 생기는데,
대체 다량의 데이터는 어떻게 수집을 하는 걸까?
기업이야 제공하고 있는 서비스에 Tag를 붙이는 것만으로도
엄청난 사용자 데이터를 모을 수 있다지만,
개인은 빅 데이터를 모으기조차 어려운 게 현실이다.
이런 개인이 가장 쉽게 데이터를 모으는 방법은
데이터를 제공하는 사이트에 들어가거나
직접 모으는 방법이 있다.
데이터를 제공하는 사이트
- 대한민국 국가통계포털(https://kosis.kr/index/index.do)
- 한국교육학술정보원(http://www.riss.kr/index.do)
- Kaggle(https://www.kaggle.com/)
하지만 데이터를 제공하는 사이트에서
원하는 자료를 딱 맞게 찾기란 매우 어렵다 보니,
원하는 자료를 웹에서 직접 모으는 대표적인 방법이
바로 크롤링(Crawling)이 되겠다.

Python 등을 활용해 웹에 접속하여
공개되어 있는 정보들을 수집한 뒤
자신이 원하는 정보만을 추리면 된다.
주의할 점은 법적 분쟁의 소지가 있으니
중요 데이터는 개인 용도로만 사용할 것.
이렇게 모은 데이터를 기반으로 특정 자료를 뽑아보고
가설을 세운 뒤 해당 가설이 맞는지 검증하면 되는 것이다.
Manta의 데이터는 자료의 양이 충분하지 않다고 판단하여
Naver Webtoon의 자료를 가져와봤다.

벌써 머리가 아픈 분도 계실 테지만 걱정하지 마시라.
우리는 기술의 시대에 살고 있으니.
우리가 할 것은 그저 데이터를 구글 시트에 옮겨 넣고,
분석해 주는 사이트로 넣기만 해도 표로 만들 수 있다.


구글의 강력한 연동 시스템을 이용하면
Sheet - Looker Studio로 자료를 이동하여
바로 표로 만들 수 있다.
자료를 만들기 전에 주의할 점은
데이터를 어떤 기준으로 뽑아볼지 미리 생각해야 한다.
예를 들면 아래와 같다.
장르별로 보면 Subscribers가 가장 높은 장르가 있을 것이고,
Likes는 시리즈가 아닌 에피소드 별로 집계하기에
Subscribers / 장르별 Count Record를 구해보면
실제 장르의 인기 척도를 알 수 있을 것이다.
이렇게 측정할 지표를 선택하고 데이터를 뽑았다면,
더욱 세분화해보아야 한다.
연재가 완료된 시리즈는 현재 트렌드에 반영하기 쉽지 않으니,
연재되고 있는 요일별 시리즈를 기준으로 다시 통계를 내보아야 한다.

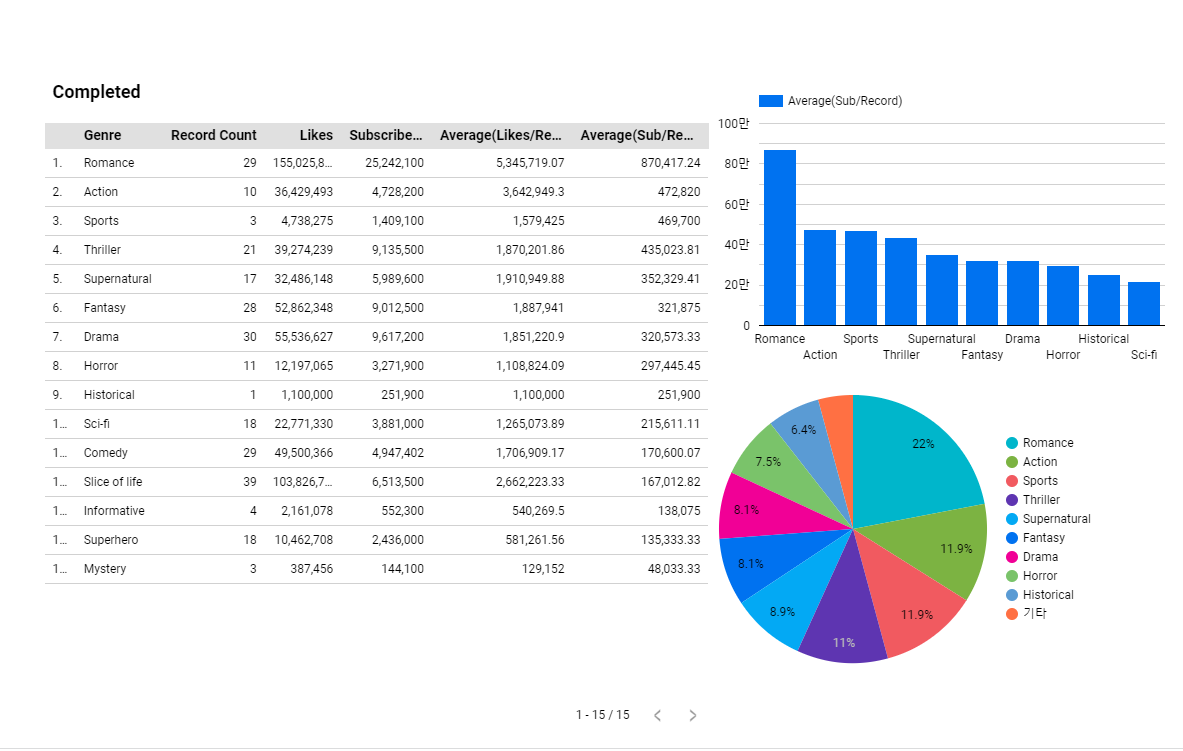
표본 수가 10개 정도로 너무 적은 장르도 있어 신뢰도가 낮지만,
재미있게도 1위를 꾸준히 유지하는 Romance와는 다르게
Fantasy는 Average(Subscribers/Record Count) 순위가 꽤 떨어진다.
연재되고 있는 시리즈 개수가 95개인 것과는 별개로 말이다.
이런 분석 자료를 활용하여
기획 중인 Push Alarm 서비스의 시리즈를 선정할 때
Daily Updated 순위를 반영한 뒤 Test를 해볼 수 있다.

하지만 이런 데이터를 기반으로 테스트할 때 주의할 점이 있는데,
데이터 분석 자료를 맹신하면 안 된다는 것이다.
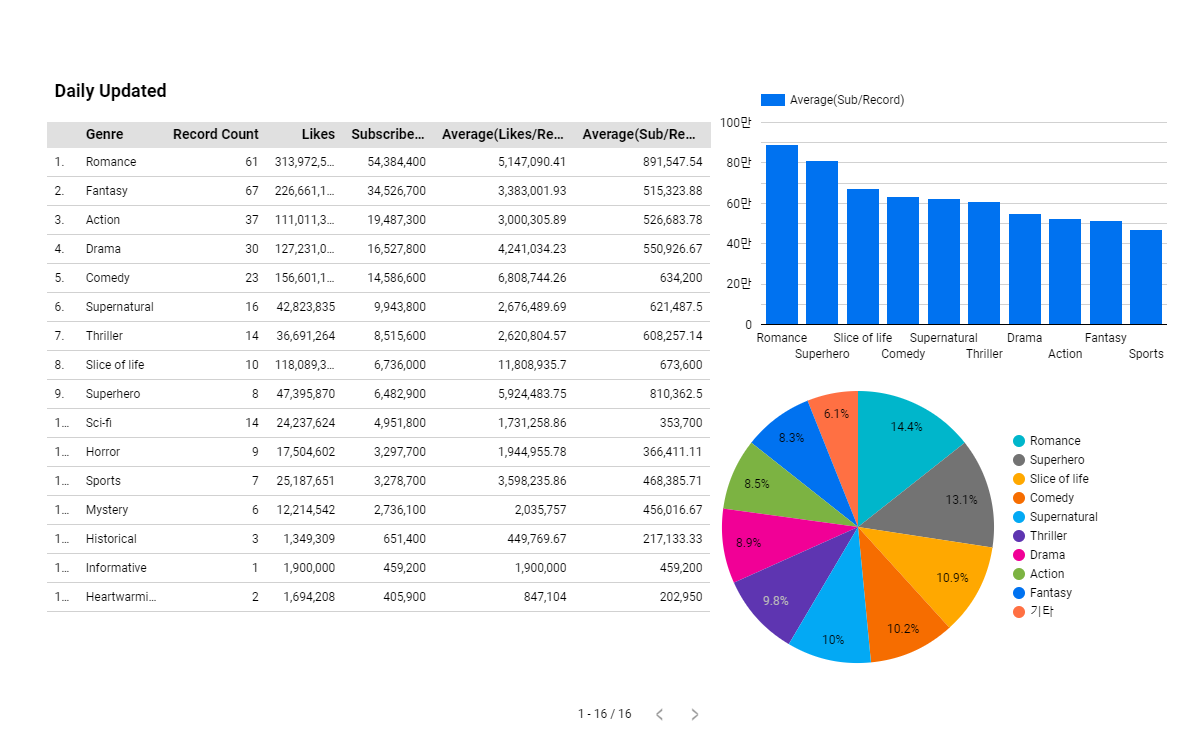
구독자가 가장 많은 순서는
Romance / Fantasy / Action / Drama / Comedy이고
가장 큰 집단 순서로 Push를 보내는 것이 훨씬 효율적일 수도 있다.
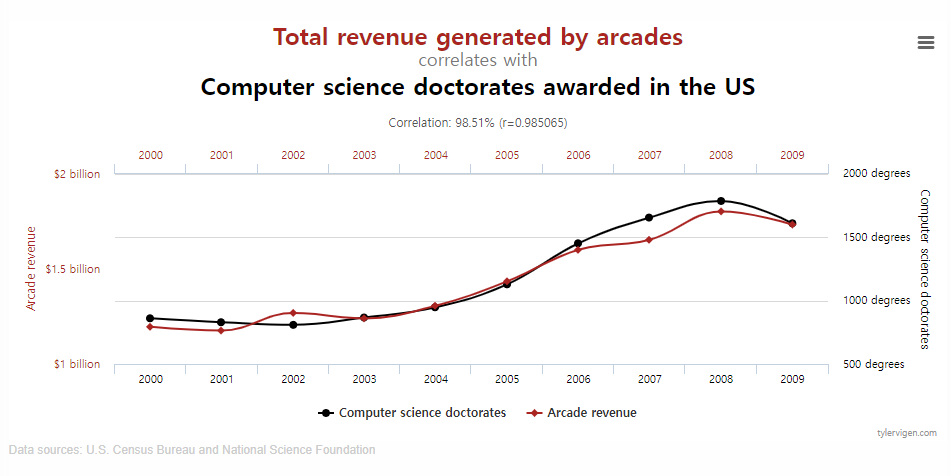
소위 말하는 A/B Test니 뭐니 하는 것들도
데이터를 기반으로 의사를 결정하지만
결과가 인과관계를 꼭 설명하는 것은 아니란 점을 기억해야 한다.
(아래는 아무 연관이 없는데 비슷하게 생긴 그래프들을 모아놓은 사이트다.)
(https://www.tylervigen.com/spurious-correlations)
최근에 나오는 ChatGPT나 Copilot 등
단순 작업들은 기계, AI가 훨씬 더 잘하는 시대가 올 것이고,
우리는 데이터를 분류하는 단순 작업을 넘어서
데이터를 분석하고 활용하는 통찰력을 기르는 게
인간으로서 필수 능력이 되지 않을까 한다.
'Code States' 카테고리의 다른 글
| Product Management Research #10 (서비스 확장 / API) (0) | 2023.05.22 |
|---|---|
| Product Management Research #9 (Python - Crawling / HTML) (0) | 2023.05.18 |
| Product Management Research #7 (Lean Startup / Manta - Funnel, AARRR 분석) (0) | 2023.05.03 |
| Product Management Research #6 (Manta - Storyboard) (0) | 2023.04.27 |
| Product Management Research #5 (Youtube - BMC) (0) | 2023.04.19 |